The Uncomfortable Question
When Yann LeCun published his position paper on autonomous machine intelligence in 2022, the AI community split into two camps. One camp dismissed it as philosophy without implementation — "nice theory, where's the code?" The other nodded along, recognizing that autoregressive token prediction was never going to produce systems that actually understand the world.
LeCun's core thesis was deceptively simple: intelligent systems need an internal model of the world. Not a probabilistic next-token predictor — a structured, energy-minimizing architecture that can plan, predict consequences, and adapt without retraining from scratch.
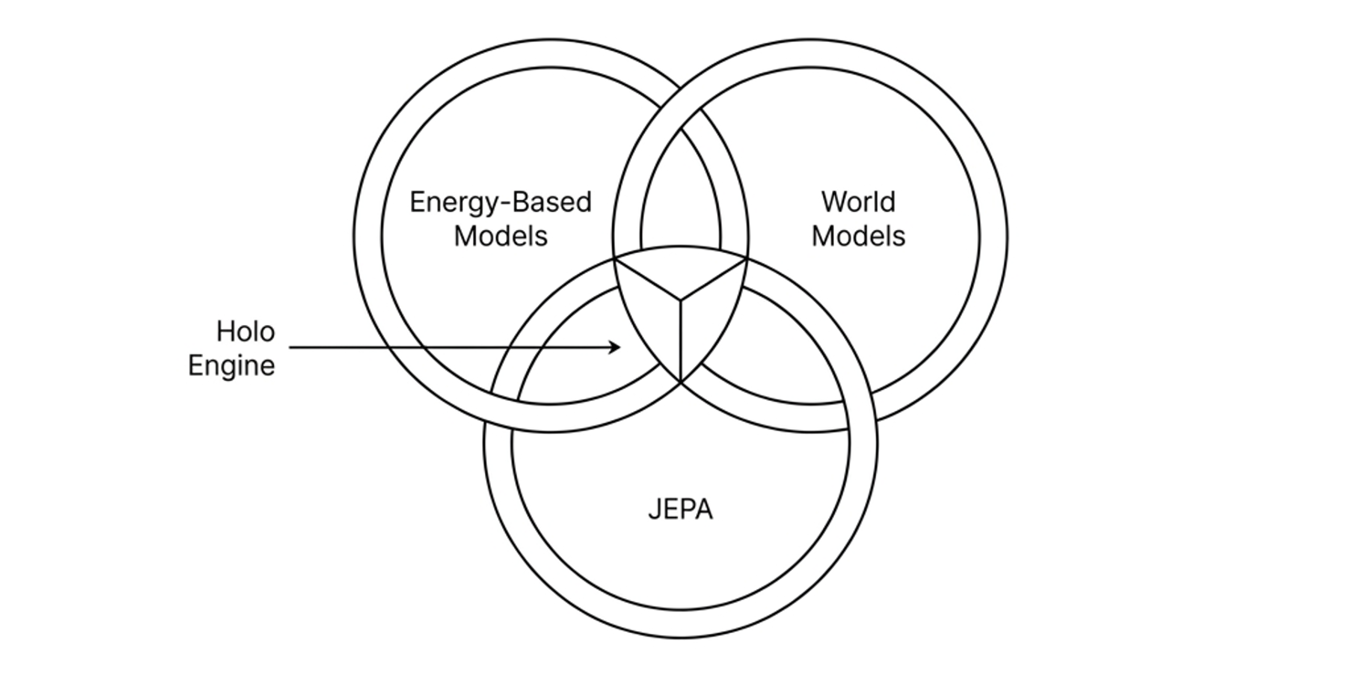
He called this vision JEPA — Joint Embedding Predictive Architecture. Its theoretical backbone: Energy-Based Models. Its aspiration: World Models that work.
We claim that Holo Engine's approach is mathematically equivalent to what the top frontier AI labs are now working on. Bold? Let's do the math.
What Even Is an Energy-Based Model?
The idea of describing systems through energy comes from statistical physics. The Ising model (1925) and the Gibbs distribution laid the groundwork for what would later be called EBMs. In machine learning, these ideas were first applied by John Hopfield (Hopfield network, 1982) and Geoffrey Hinton (Boltzmann machine, 1985) — they used "energy" to describe the states of neurons.
Strip away the hype, and an EBM is embarrassingly elegant. You have data x, a hypothesis y, and a scalar function E(x, y) that assigns low energy to correct pairs and high energy to incorrect ones. Inference is minimization: find the y that makes E smallest. Learning is landscape shaping: adjust the energy surface so the right answers sit in valleys and the wrong ones sit on hills.
At inference time — just a surface with valleys in the right places. No softmax, no sampling. But at training time, things get ugly: shaping the landscape without mode collapse turned out to be devilishly hard, and most approaches (contrastive divergence, score matching) still require hyperparameter tuning, including temperature.
But what if you didn't need to train the landscape at all? What if the geometry of your data structure was the energy landscape?
Enter the Twin: Where the Energy Comes From
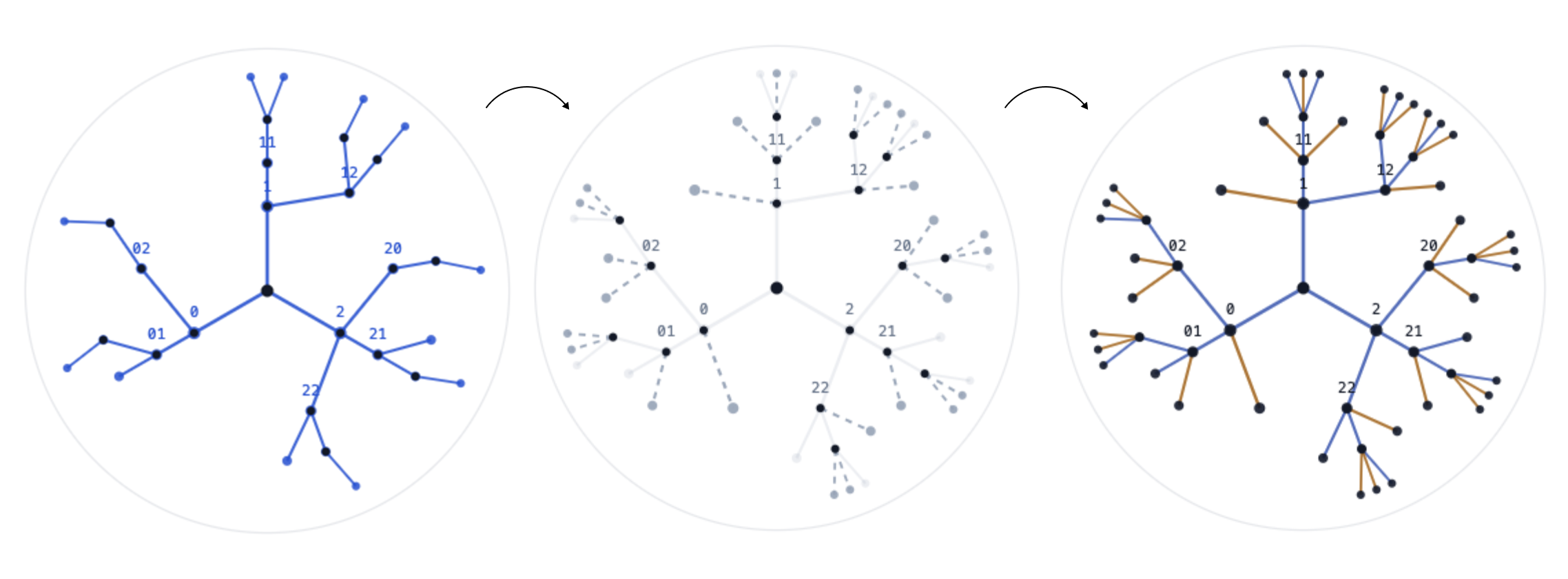
Holo Engine is built on a mathematical object called the p-adic Twin. Here's the construction in plain English:
- Your data arrives as a stream of observations. Each observation activates branches in a rooted p-ary tree (think: a hierarchical address space, like a file system with exactly p folders at each level).
- This observed subgraph
C is sparse — it only contains paths the data has actually walked.
- The Twin
T is the minimal completion that fills in exactly the missing branches at every active node, restoring full local branching.
The governing constraint is one line:
$$\deg^+_C(v) + \deg^+_T(v) = p$$
At every active node, the number of observed outgoing edges plus the number of Twin-filled edges equals exactly p. That's the invariant. It's local, it's deterministic, and it's computationally trivial to maintain.
Why does this matter? Because once you have a complete local basis at every node, three things become possible: you can define a full hypothesis space, you can build bulk geometry via barycentric relaxation, and — crucially — you can define an energy function.
The Energy Function — Not a Metaphor
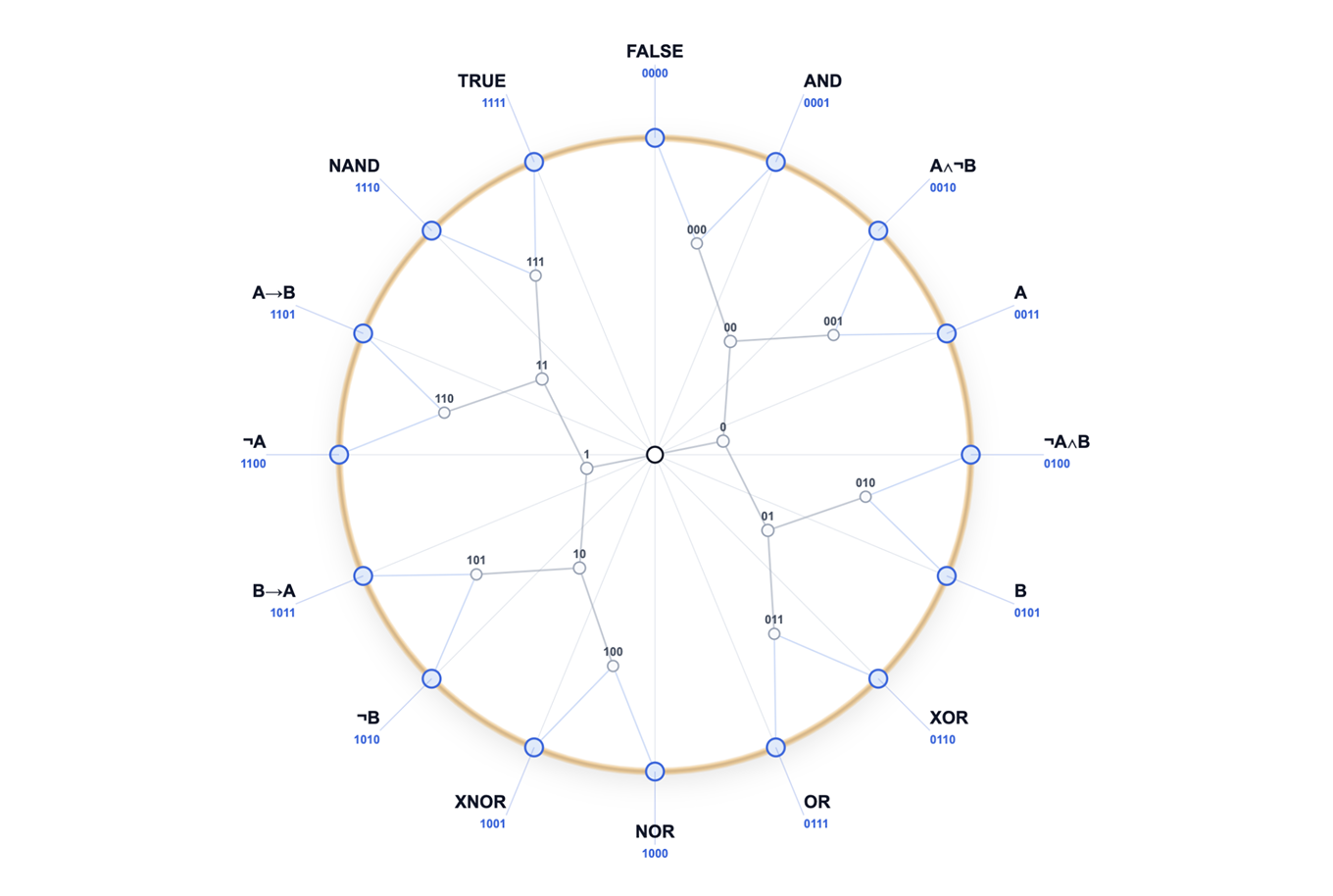
In the binary case (p=2), the tree of depth 4 has exactly 16 leaves. Each leaf corresponds to one of the 16 Boolean functions of two variables (AND, OR, XOR, NAND, ...). The truth table of each function is literally its leaf address.
Each Boolean function can be represented in Algebraic Normal Form (ANF) with coefficients c = (c₀, c₁, c₂, c₃). Converting these to ℤ₂-phases:
$$q_i = (-1)^{c_i} \in \{\pm 1\}$$
Logic becomes phase interference: the output of any Boolean function on any input is computed as a product of activated phases. No lookup table — multiplicative interference of spins.
Here's where it becomes an EBM. Define continuous fields s_i ∈ ℝ and soft phases q_i = tanh(β·s_i). The energy:
$$E(s) = \sum_x \bigl(\hat{f}_s(x) - y(x)\bigr)^2 + \lambda \sum_i \bigl(1 - q_i(s)^2\bigr)$$
The first term is reconstruction error — how well the current phase configuration reproduces the target truth table. The second term is bi-attractor regularization — it pushes each soft phase toward ±1, stabilizing memory.
Learning dynamics:
$$\dot{s} = -\Sigma \cdot \nabla_s E(s) + \Xi \cdot \eta(t)$$
This is Langevin dynamics. Σ is dissipation. Ξ·η(t) is stochastic exploration. The stationary point s* satisfies sign(q(s*)) = (−1)^c(f) — the system relaxes into the correct logical configuration.
Key insight: This isn't an "analogy" to EBMs. This is a continuous Energy-Based Model with Langevin sampling. The energy landscape is defined by the Twin structure, not by gradient-trained parameters. The landscape is correct by construction.
Selected function
Function:—
ANF c:—
Phases q:—
Truth table:—
Energy
Low (valley)High (hill)
Select a Boolean function
From Flat Logic to Hyperbolic Geometry
The boundary algebra gives you logic. But Holo Engine doesn't stop at the boundary — it builds bulk geometry on the Poincaré disk.
After Twin completion seals the boundary, internal tree nodes get positioned via hyperbolic barycenters of their children. Leaves sit near the disk boundary. Parents sit closer to the center. The deeper the abstraction, the closer to the origin.
This creates a natural hierarchical latent space where:
- Hyperbolic distance = semantic distance (exponential volume growth means fine-grained distinctions at the boundary, coarse abstractions at the center)
- Geodesics encode logical relationships between concepts
- New data points find their position via energy minimization — exchange relaxation:
$$E_{\mathrm{ex}}(q_u) = \sum_{v \in \mathrm{child}(u)} |q_u - q_v|^2 + \lambda\,(1 - |q_u|^2)$$
Internal nodes relax their states to be consistent with their children. Laws and abstractions emerge as attractors of this relaxation — they live near the center of the disk, while raw observations live near the boundary.
The JEPA Connection: Predicting Missing Structure
LeCun's JEPA has a specific architecture: an encoder maps observations to latent space, and a predictor infers missing latent representations from observed ones. Prediction happens in latent space, not pixel space — you predict structure, not raw data.
Now look at the Twin:
JEPA (LeCun)
Encoder
Maps observation x → latent representation sx
Holo Engine
Sensor → Subgraph C
Raw data activates branches in p-ary tree → hierarchical encoding
JEPA (LeCun)
Predictor
Predicts ŝy from sx in latent space
Holo Engine
Twin Completion T
Predicts missing branches from observed. predict(missing | observed).
JEPA (LeCun)
Hierarchical Latent
Multi-level abstractions in embedding space
Holo Engine
Poincaré Bulk
Hyperbolic barycenters: depth = abstraction level. Exponential capacity.
The structural parallel is precise: JEPA predicts missing vectors in embedding space. The Twin predicts missing branches in tree space. Both operate on latent structure, not raw observations. Both use hierarchy as their organizing principle.
The difference? JEPA's predictor is a learned neural network. The Twin's predictor is a one-line deterministic invariant. One needs millions of parameters and GPU-months. The other needs arithmetic.
Architectural analogy — not an isomorphism, but deep structural alignment with shared mathematical intuitions.
The Determinism Argument
LeCun's deepest critique of LLMs isn't about capability — it's about architecture. Autoregressive models are constitutionally unable to plan, because they can only generate left-to-right. They hallucinate because they're sampling from a distribution, not minimizing an energy function. They can't verify their own outputs because they have no internal model of consistency.
Holo Engine's position on this isn't marketing alignment — it's shared philosophical ground:
- Zero hallucinations. Deterministic. Same input → same output. Always.
- Built-in verification. Every output has a mathematical derivation path. You can trace why any classification was made.
- Energy minimization, not token prediction. Inference is relaxation toward a fixed point — not sequential generation of symbols.
"The world has underlying deterministic structure. AI should reflect that structure, not approximate it with probabilities."
This isn't a manifesto. It's a design choice — one that aligns with what the fathers of AI have argued for decades, from Minsky's "Society of Mind" to LeCun's "A Path Towards Autonomous Machine Intelligence."
Why This Matters Now
The AI industry is hitting scaling walls. GPT-5 costs more than some countries' GDP to train. Inference costs eat margins. Hallucination rates remain non-zero for mission-critical applications. The fundamental question — "can we build systems that actually reason?" — remains open.
Holo Engine sidesteps the problem. The energy landscape isn't learned — it's constructed from the geometry of data itself. The Twin invariant guarantees completeness. Hyperbolic embedding guarantees hierarchy. Dissipative relaxation guarantees convergence. We believe that, mathematically, this is thinking that "flows toward solutions."
Is this the World Model LeCun envisioned? Probably not in full generality — not yet. But it's a working implementation of the principles he articulated: energy minimization, structured latent prediction, hierarchical abstraction, deterministic reasoning.
Summary of Verdicts
| Claim |
Verdict |
Evidence |
| Holo Engine is an EBM |
Mathematically strict |
Dissipative relaxation + energy landscape + Langevin dynamics. Formal proof in twin_theory §6. |
| Holo Engine is a JEPA |
Structural analogy |
Hierarchical hyperbolic latent space + structural predictor (Twin). Shared architecture, not isomorphism. |
| Holo Engine is a World Model |
Functional |
Forward prediction (symbolic regression) + planning (CSP) + online adaptation. Scope: physics, agents. |
| Determinism as philosophy |
Shared ground |
Same critique of probabilistic AI as LeCun. Implemented, not just stated. |
What Comes Next
If you're building AI agents and you're tired of hallucination patches, prompt engineering hacks, and non-deterministic outputs — there's now a mathematical alternative. It won't write your emails. But it will solve your constraints, discover your formulas, and verify your logic. Deterministically. Every time.
The question isn't whether Energy-Based Models are the future. LeCun already answered that. The question is whether they need trillion-parameter training runs — or whether the geometry of the data itself is enough.
We bet on geometry. So far, it's working.